My Magic: The Gathering cube analyzer was finally complete. After weeks of work, it had evolved from a simple script into a sophisticated web application, live at mtg.scottliu.com/cube/recommend. It had a snappy UI, a hybrid scoring engine with pre-computation and a "live tuning" mode, and a hyper-optimized query system. It was, for all intents and purposes, done.
And then the elephants showed up. Or rather, they didn't.
While using the tool, I stumbled on a card called "Call of the Herd." It’s a classic green creature-maker. For some reason, I found myself staring at its art -- two elephants in a forest -- for an uncomfortably long time. Their eyes started to look... creepy. Sentient, even. It was the kind of mild delirium that only sets in when you're on the verge of discovering a bug that makes no logical sense.

This was the beginning of a truly flabbergasting mystery.
The Crime Scene
Here was the paradox. Using my new "Card Lookup" tool, I checked the score for "Call of the Herd." It was a very respectable 0.890.
Then, I went to the "Recommended Adds" page and filtered by "Green." The list of recommendations loaded, with scores ranging from 0.925 down to 0.813 on the first page.
"Call of the Herd," with its score of 0.890, should have been sitting comfortably in the middle of that list. But it wasn't there. It wasn't on page two, either. It was simply... gone.
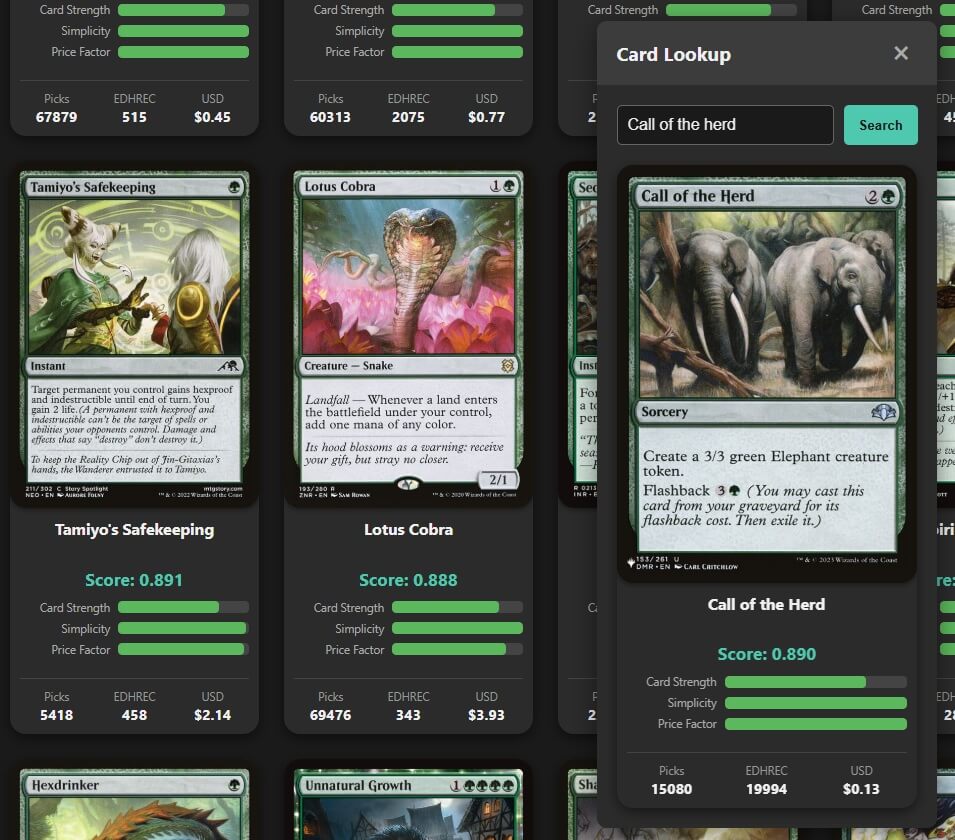
This shouldn't have been possible. The system was telling me two contradictory facts. It was like arriving at a crime scene to find the victim had somehow locked the door from the inside. I put on my detective hat, poured a cup of coffee, and began the investigation.
The Investigation
Every good investigation starts by ruling out the obvious.
Suspect #1: A Simple Rule-Breaker? My first suspicion was that the card was a known offender. I had a long list of "house rules" hard-coded into the analyzer: no cards with a vintage frame, no multi-faced cards, no cards with a list of banned keywords. Was "Call of the Herd" secretly one of them?
I spun up a dedicated diagnostic script to check the card against every single rule. The results came back clean.
is_in_cube = 0? Pass.frame = '2015'? Pass.num_faces = 1? Pass.
The card had a perfect alibi. It wasn't a simple rule-breaker.
Suspect #2: The Heuristic Dragnet?
My next suspect was my own clever optimization. To keep the app fast, the "Adds" query first finds a "shortlist" of the top 500 candidates before applying the slow text filters. Was it possible that in the vast "Sea of Green" cards, "Call of the Herd" was ranked #501 and just missing the cutoff? I cranked the CANDIDATE_POOL_SIZE up to a massive 5000 -- a dragnet wide enough to catch anything. I refreshed the page.
Still no elephants. The card wasn't just slipping through the net; it was never in the ocean to begin with.
Suspect #3: A Case of Mistaken Identity?
At this point, you start questioning reality itself. Maybe the card wasn't really green. Maybe some obscure Flashback rule gave it a weird color identity in the database that my filters were catching. I fired up the SQLite console and checked its vitals. color_identity: 'G'. It was exactly who it said it was.
The Epiphany
I had exhausted every lead. The card passed every filter, it had a high score, it wasn't being cut off by the heuristic, and its identity was correct. I was out of options. The only thing left to do was to look deeper, to get the ground truth. It was time to dust for prints on the query itself.
To do this, I added a few log lines to the application to print the exact, final SQL query being sent to the database. And then, a stroke of luck. While trying to view this new output, I happened to look at the main systemd service logs for the first time in a while. And there it was. A single, critical line I had overlooked:
(!) WARNING: Formula has changed. Using slower 'Live Tuning Mode'.
The call was coming from inside the house.
The entire time, I had been the victim of a classic caching problem of my own creation. The case broke wide open:
- The Motive: A few days prior, I had tweaked my scoring formula, making it much stricter. I never re-ran the bootstrap script to "finalize" this new formula.
- The "Live" Reality: The main "Adds" list correctly detected this change and entered "Live Tuning Mode," scoring all the green cards with my new, stricter formula.
- The Blind Spot: The Card Lookup tool, however, had a bug born from my own mental blind spot. When I implemented it, I had completely forgotten about the hybrid engine. In my mind, looking up a card was as simple as fetching a value from the database. I wasn't performing the hash check, so it was naively displaying the old, stale, pre-computed score of 0.890 that was still sitting in the database.
I wasn't comparing one score to a list of scores. I was comparing a score from one reality to a list of scores from another.
The mystery was solved. The "impossible" paradox was just an illusion. "Call of the Herd" wasn't missing from the list. I re-ran my bootstrap script: its true, re-calculated score was actually 0.810 -- not high enough to make the cut. It had been correctly excluded the entire time.

The Resolution
The fix was a simple but powerful refactoring. I centralized the hash-checking logic into a core function. Now, both the main analyzer and the card lookup tool use the same source of truth, guaranteeing their results are always in sync, whether running in the fast pre-computed mode or the flexible live-tuning mode.
It was an immensely satisfying end to a truly confounding mystery. It's a powerful reminder that in any complex system, the most baffling bugs are often not in the code you're looking at, but in the assumptions you've forgotten you made.
And as for the elephants? Their eyes don't look so creepy anymore. Now I can finally get back to the actual work of sleeving cards.